What are large language models?
The realm of language models (LMs), particularly in the field of natural language processing, has been witnessing significant advancements. These models are probabilistic systems designed to identify and learn statistical patterns in language.

The current success of LMs positions them as comprehensive understanding systems of natural language, even though they are trained using simple logic. The core challenge with training large language models, unsurprisingly, is the requirement for high-quality data.
Self-Supervised Learning and Pre-Trained Language Models
The solution to this problem is self-supervised learning, a method that enables models to learn from unannotated text. In contrast to relying on manually labeled data, this technique is not limited by data scarcity or cost. The process involves feeding a large corpus of text to the model and tasking it with predicting the next word in a sentence. As the model goes through multiple examples, it learns to internalize various linguistic patterns, rules, and relationships between words and concepts. The result of this process is a pre-trained language model, which provides a foundational understanding of natural language.
The creation of such pre-trained models, sometimes referred to as foundation models, is a crucial step. However, these models cannot be used for advanced use cases right off the bat. The next step is to fine-tune them for specific tasks or to adapt their non-specialized knowledge to a specialized domain.
Fine-Tuning and Transfer Learning
Fine-tuning involves further training of the pre-trained model on a smaller, task-specific, labeled dataset using supervised learning. A common application of fine-tuning is machine translation, where a pre-trained language model is fine-tuned on a parallel corpus containing sentences in both the source and target languages. Through this process, the model learns to map linguistic structures and patterns between the two languages, enabling it to translate text effectively. Another common use of fine-tuning is in adapting a pre-trained model to technical or specialized knowledge domains like medical or legal fields.
The fine-tuning process is an example of transfer learning, a fundamental concept in modern deep learning. This concept allows the model to leverage knowledge gained from one task and apply it to another, often with minimal additional training.
Dataset for training LLMs
| Corpora | Size | Source | Updated |
|---|---|---|---|
| BookCorpus | 5GB | Books | Dec-15 |
| Gutenberg | -- | Books | Dec-21 |
| C4 | 800GB | CommonCrawl | Apr-19 |
| CC-Stories-R | 21GB | CommonCrawl | Sep-19 |
| CC-News | 78GB | CommonCrawl | Feb-19 |
| REALNEWs | 120GB | CommonCrawl | Apr-19 |
| BigQuery | -- | Codes | Mar-23 |
| the Pile | 800GB | Other | Dec-20 |
| ROOTS | 1.6TB | Other | Jun-22 |
The Rise of Transformer-based Language Models
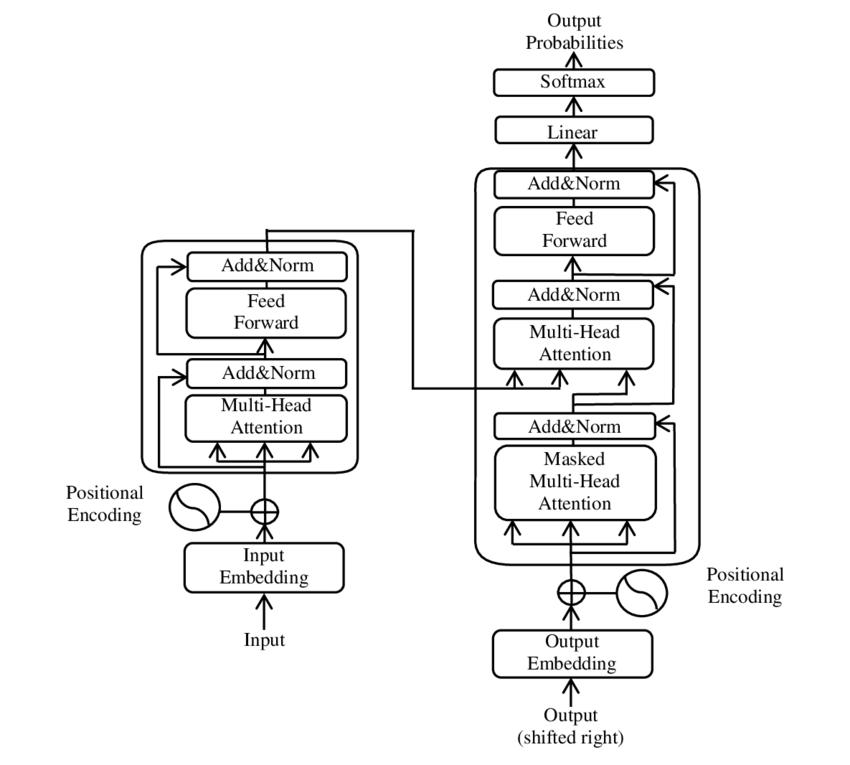
The underlying architecture of modern language models is largely based on artificial neural networks. Specifically, the Transformer model, invented in 2017, has played a significant role in this domain. Two key components that contribute to the success of transformers are the attention mechanism and word embeddings. Word embeddings capture semantic and syntactic properties of words through high-dimensional vector representations, while attention mechanisms allow the model to weigh the importance of different words or phrases in the text.
Transformer-based language models employ an encoder-decoder architecture to process and generate text. Depending on the task, a language model might use only the encoder part, the decoder part, or both. For example, the BERT model uses the encoder part of a transformer, while GPT uses the decoder.
The Future of Language Models
The development of language models in recent years has been marked by a substantial increase in size as measured by the number of parameters. This trend started with models like the original GPT and ELMO, which had millions of parameters and progressed to models like BERT and GPT2 with hundreds of millions of parameters. Some of the latest models like Megatron, Turing NLG, and Google's Palm have already surpassed 500 billion parameters.
However, recent research has shown that the size of the dataset also plays a crucial role in model performance. For optimal results, every time the number of parameters doubles, the data size should also double. This suggests that the amount of training data needed for training could become a key bottleneck for these AI systems.
Despite these challenges, large language models have shown remarkable abilities. They can perform sophisticated tasks and exhibit new capabilities that seem to emerge in a discontinuous manner, unlike the predictable linear improvement of quantitative metrics. These skills are acquired through exposure to recurring patterns in natural language during the training process, without explicit task-specific supervision.
However, fine-tuning the model on a small dataset of examples helps it better understand and follow instructions given in natural language. It's also crucial to ensure these models are not used for malicious purposes and are designed to decline any prompts that could lead to harm.
As these models continue to evolve, it's important to harness methodologies like reinforcement learning from human feedback to address safety concerns and align these models with human values. The intricacies of large language models are vast and interconnected, promising exciting advancements and potential for the future. Stay tuned for future discussions on these developments in the deep learning space.