Sequence Classification Using RNNs with FastAI
Implementing an RNN for sequence classification in Python using the FastAI library
Sequence classification is an important task in natural language processing and time series analysis. It involves taking a sequence of data points, like words in a sentence or values over time, and assigning a categorical label to the whole sequence. Recurrent neural networks (RNNs) are a powerful type of neural network well-suited for sequence classification tasks. In this blog post, we'll walk through implementing an RNN for sequence classification in Python using the fastAI library.
Overview of Sequence Classification
In sequence classification, we want to take a sequence of inputs x1, x2, ..., xn and map it to a categorical output y. Some examples include:
- Sentiment analysis: Classify a sentence as expressing positive or negative sentiment
- Activity recognition: Classify a sequence of motion sensor data to an activity like walking or running
- Time series classification: Classify segments of time series data like ECG signals to normal or abnormal patterns
The key challenges are handling variable-length input sequences and learning temporal relationships between inputs. RNNs are designed to address these challenges.
Recurrent Neural Networks

Recurrent neural networks (RNNs) are a type of neural network well-suited for processing sequential data. They operate on an input sequence one step at a time, maintaining an internal hidden state that encodes information about previous steps. This allows RNNs to learn temporal relationships between inputs that are separated by arbitrary distances in the sequence.
Some key components of RNNs are:
- Hidden state: Encodes information about the sequence seen so far. It's updated after processing each input.
- Recurrence formula: Defines how to update the hidden state given the previous state and current input. Common choices are LSTM and GRU cells.
- Output layers: Maps the hidden state at each step to an output, like a predicted label after the last step.
This recurrence allows RNNs to maintain useful representations of arbitrary length sequences. The downside is RNNs can be difficult to train properly due to issues like exploding/vanishing gradients. Various RNN architectural tricks address these issues.
LSTM Networks
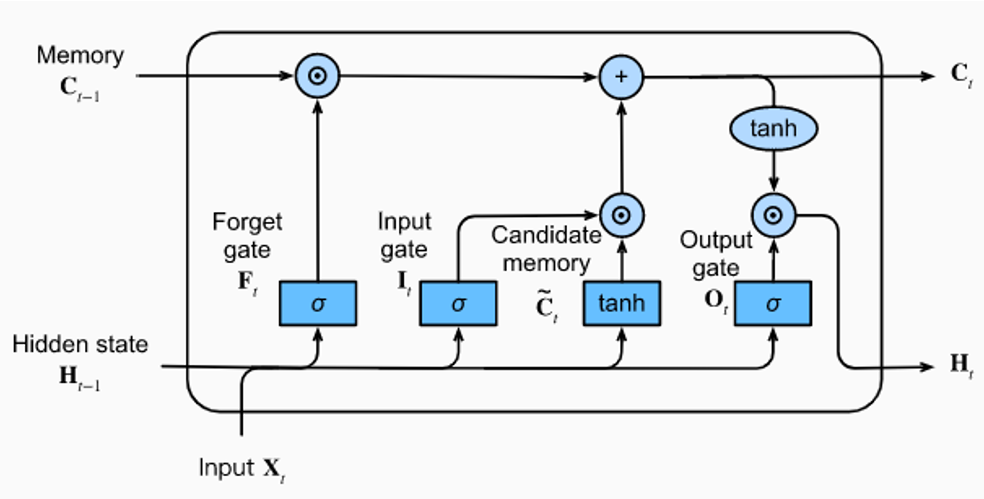
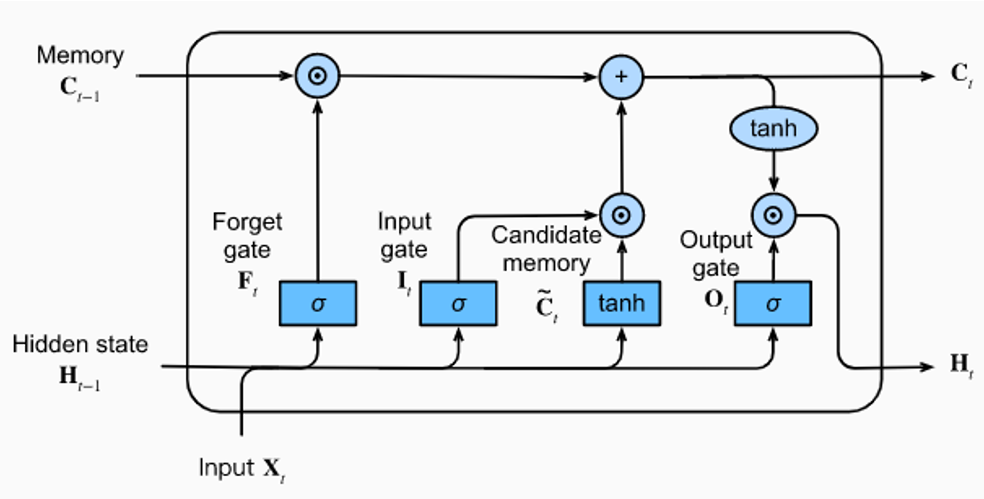
A common RNN variant is the Long Short-Term Memory (LSTM) network. LSTMs incorporate a memory cell and gates that allow them to better retain long-range dependencies in sequences. Here's a quick overview of how LSTMs work:
- Cell state: Like the standard hidden state, but carefully maintained via gates.
- Gates: The input, output, and forget gates control how information flows in, out, and through the cell state. This helps preserve gradients during training.
- Non-linearities: Sigmoid and tanh activation functions help regulate information flow.
LSTMs don't inherently provide better sequence modeling than standard RNNs, but their gating mechanisms make them much easier to train properly. They are very commonly used for sequence tasks like translation, captioning, and classification.
Loading IMDb Data
The IMDb dataset contains 25,000 movie reviews annotated with binary sentiment labels - positive or negative. Reviews have variable lengths, so this is a great sequence classification task for RNNs.
The fastai library provides a formatted version of the IMDb data in its datasets module. We can easily load it with just a few lines of code:
from fastai.text.all import *
path = untar_data(URLs.IMDB)
path.ls()
(path/'train').ls()
dls = TextDataLoaders.from_folder(untar_data(URLs.IMDB), valid='test')
dls.show_batch()- This code snippet sets up the data preparation stage for NLP tasks using the fastai library.
- It downloads, extracts, and organizes the IMDb dataset for training and validation.
- It creates data loaders to efficiently feed the data into a machine-learning model.
- It provides a way to preview the data to ensure it's ready for the next steps.
Creating an LSTM with fastai
variable-length
The text_classifier_learner provides a convenient way to create a RNN classifier model in fastai. Under the hood, it uses PyTorch and AWD-LSTM, but we can treat it as a black box LSTM.
First, we'll define our model architecture:
learn = text_classifier_learner(dls, AWD_LSTM, drop_mult=0.5, metrics=accuracy)
learn.fine_tune(4, 1e-2)
The model takes word indices as input, passes them through an embedding layer, feeds the embeddings into an LSTM, and then feeds the final LSTM hidden state into a linear layer to make a prediction.
Now we can create the learner object, which handles model training for us:
With our LSTM model and data ready, we can now train the classifier by calling .fit() on the Learner object.
learn.show_results()
learn.predict("I really liked that movie!")Limitations of RNN
Recurrent Neural Networks (RNNs) and Long Short-Term Memory (LSTM) networks are powerful tools for sequential data processing, but they come with several limitations:
- Vanishing Gradient Problem: RNNs, including LSTMs, are susceptible to the vanishing gradient problem. When training deep networks or networks with long sequences, gradients can become extremely small during backpropagation, causing the network to have difficulty learning long-range dependencies.
- Exploding Gradient Problem: In contrast to vanishing gradients, there's also the possibility of gradients becoming too large, leading to numerical instability during training. This is known as the exploding gradient problem.
- Difficulty in Capturing Long-Term Dependencies: While LSTMs are designed to address the vanishing gradient problem to some extent, they still struggle to capture very long-term dependencies in sequences. Gated Recurrent Unit (GRU) and Transformer models are alternatives that have been proposed to address this issue.
- Sequential Processing Speed: RNNs and LSTMs process sequences sequentially, which can be slow for long sequences. This can make them less suitable for real-time applications where low latency is critical.
- Limited Parallelization: Due to their sequential nature, RNNs and LSTMs are not easily parallelizable during training, which can lead to longer training times compared to other network architectures like feedforward neural networks or convolutional neural networks (CNNs).
- Difficulty with Irregular Time Series: RNNs and LSTMs assume regular time intervals between data points in a sequence. They may struggle to handle irregularly sampled time series data efficiently.
- Memory Consumption: LSTMs can be memory-intensive, especially when dealing with very long sequences or deep networks. This can lead to practical limitations, particularly on hardware with limited memory.
- Hyperparameter Sensitivity: RNNs and LSTMs have several hyperparameters (e.g., the number of hidden units, learning rate, sequence length) that need to be tuned carefully to achieve good performance. Finding the right set of hyperparameters can be challenging.
- Lack of Global Attention Mechanism: LSTMs do not naturally have a built-in global attention mechanism, which can make them less effective in tasks that require focusing on specific parts of a sequence while ignoring others. Transformers have gained popularity for such tasks due to their self-attention mechanism.
- Limited Understanding of Context: LSTMs, like other neural networks, are often considered "black-box" models, making it difficult to interpret how they arrive at their predictions. This lack of interpretability can be a limitation in applications where understanding the model's reasoning is important.
Hyperparameter Optimization for RNN
To find the best parameters for an RNN, there are several strategies that can be used:
- Grid search: This involves systematically trying different combinations of hyperparameters (such as learning rate, regularization strength, and number of hidden units) and selecting the combination that performs best on a validation set.
- Random search: Similar to grid search, but instead of trying all possible combinations of hyperparameters, a subset of combinations is sampled randomly. This can be more efficient than grid search, especially when the number of hyperparameters is large.
- Bayesian optimization: This is a more sophisticated approach that uses Bayesian inference to model the relationship between hyperparameters and validation set performance. The optimization algorithm then selects hyperparameters that are likely to result in good performance, based on the posterior distribution over possible hyperparameter values.
- Gradient-based optimization: This involves using gradient-based optimization algorithms (such as stochastic gradient descent or Adam) to adjust the network's weights during training. These algorithms can automatically adjust the learning rate and other hyperparameters based on the network's performance on the training set.
Summary
In this blog, we walked through a complete sequence classification project from loading data to training and evaluating an LSTM model with fastai. The key takeaways are:
- LSTMs and other RNNs excel at sequence modeling tasks like text classification.
- fastai provides a high-level API for easily creating, training, and evaluating complex RNN models in PyTorch.
- Using pretrained embeddings and discrimination training, we can quickly reach >85% accuracy on IMDb review classification.
