TabNet: Attentive Interpretable Tabular Learning
Introduction
TabNet is a deep learning architecture for tabular data that uses sequential attention to choose which features to reason from at each decision step. This enables interpretability and more efficient learning, as the learning capacity is used for the most salient features. TabNet has been shown to outperform other neural networks and decision tree variants on a wide range of tabular datasets.
The official code implementation is available here
TabNet architecture
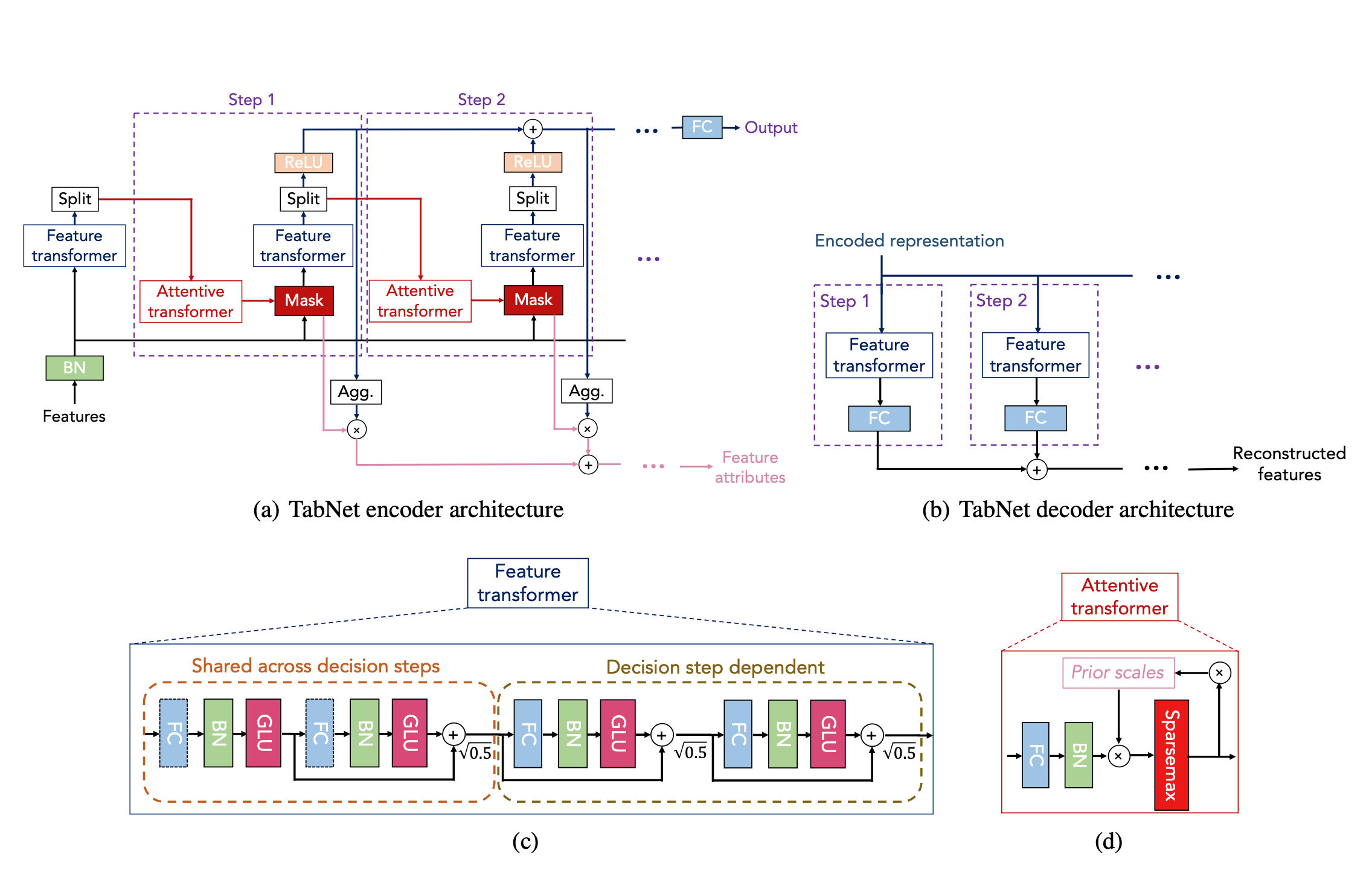
The TabNet architecture is composed of three main components:
- Feature transformer: This component transforms the input features into a more informative representation. This can be done using a variety of techniques, such as batch normalization, scaling, and one-hot encoding.
- Attentive transformer: This component uses sequential attention to select the most important features for each decision step. The attentive transformer is implemented using a sparse matrix multiplication operation, which makes it efficient for tabular data.
- Feature masking: This component masks out features that are not selected by the attentive transformer. This helps to improve the model's performance and interpretability.
The feature transformer and attentive transformer are stacked together to form the TabNet encoder. The output of the encoder is then fed to a decoder, which produces the final prediction. The decoder can be implemented using a variety of techniques, such as a fully connected neural network or a logistic regression model.
Code example
First we can install PyTorch with the following command. We use TabNet package from dreamquark.
pip install pytorch-tabnet
Then with few lines of code, we can train a tabnet model
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
iris = load_iris()
X = iris.data
y = iris.target
# Split the dataset into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
print("Training set shape:", X_train.shape, y_train.shape)
print("Testing set shape:", X_test.shape, y_test.shape)
from pytorch_tabnet.tab_model import TabNetClassifier, TabNetRegressor
clf = TabNetClassifier() #TabNetRegressor()
clf.fit(
X_train, Y_train,
eval_set=[(X_valid, y_valid)]
)
preds = clf.predict(X_test)TabNet's advantages
TabNet has several advantages over other deep learning architectures for tabular data:
- Interpretability: TabNet's feature selection mechanism makes it easy to interpret which features are most important for the model's predictions. This can be done by analyzing the feature masks that are output by the attentive transformer.
- Efficiency: TabNet only learns from the most salient features at each decision step, which makes it more efficient than other models that learn from all features at all times. This can be especially important for large tabular datasets with a large number of features.
- Performance: TabNet has been shown to outperform other neural network and decision tree variants on a wide range of tabular datasets. This is because TabNet is able to learn more complex relationships between the features in the data.
Applications of TabNet
TabNet can be used for a variety of tasks, including:
- Classification: TabNet can be used to classify tabular data into different categories. For example, it can be used to classify customers as potential churners or not, or to classify products as recommended or not recommended for a particular user.
- Regression: TabNet can also be used for regression tasks, such as predicting customer lifetime value or predicting the demand for a product.
- Anomaly detection: TabNet can be used to detect anomalies in tabular data, such as fraudulent transactions or unusual network activity.
Conclusion
TabNet is a powerful deep learning architecture for tabular data that offers interpretability, efficiency, and performance. It can be used for a variety of tasks, including classification, regression, and anomaly detection.
Example
Here is an example of how TabNet can be used for classification:
Suppose we have a tabular dataset of customer data that includes features such as customer age, gender, purchase history, and product reviews. We want to train a model to predict whether or not a customer is likely to churn.
We can use TabNet to train a churn prediction model by following these steps:
- Preprocess the data by cleaning and transforming the features.
- Split the dataset into training and test sets.
- Train the TabNet model on the training set.
- Evaluate the model's performance on the test set.
- Deploy the model to production so that it can be used to predict churn for new customers.
Once the model is trained, we can use it to predict the churn probability for a new customer by inputting the customer's data into the model. The model will output a probability between 0 and 1, where a higher probability indicates that the customer is more likely to churn.
We can also use the TabNet model's feature selection mechanism to identify the features that are most important for predicting churn. This information can be used to understand why customers are churning and to develop strategies to reduce churn.
Tips for using TabNet
Here are a few tips for using TabNet:
- Use a variety of feature transformation techniques to improve the model's performance.
- Tune the TabNet hyperparameters, such as the number of encoder steps and the attention dropout rate.
- Use the feature masks to interpret the model's predictions and identify the most important features.
- Evaluate the model's performance on a held-out test set to avoid overfitting.
References
 dreamquark-ai
dreamquark-ai