What is a Generative Adversarial Network?
Generative Adversarial Networks (GANs) are a fascinating and innovative class of artificial intelligence algorithms. They are part of the larger family of neural networks and have been especially impactful in the field of computer vision, though their applications are vast and varied. This blog post aims to demystify GANs and provide a comprehensive overview of how they work, their applications, and why they have stirred so much excitement in the tech community.
GANs were first introduced by Ian Goodfellow and his colleagues in a 2014 paper. The primary objective of a GAN is to generate new data that can pass as real data. It's like having an art forger and an art detective: one is trying to produce a counterfeit, while the other is trying to tell if it's the real thing.
How do GANs Work?
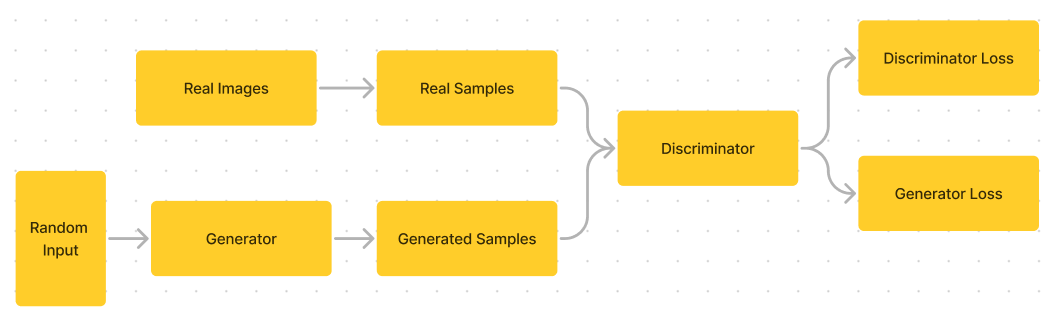
A GAN consists of two neural networks: the Generator and the Discriminator.
- Generator: Takes a random noise vector as an input and produces samples as output.
- Discriminator: Takes both real and fake samples and assigns a probability that a given sample is real.
The two networks are the generator model, which tries to synthesize realistic new data, and the discriminator model, which tries to distinguish the generator's synthetic data from real data. The networks are trained simultaneously, with the generator trying to better fool the discriminator and the discriminator trying to better identify the generator's artificial data.
During training, these two networks are in essence fighting in a cat-and-mouse game:
- The Generator tries to produce fake data that looks as real as possible.
- The Discriminator tries to get better at distinguishing real data from fake data.
- Back to step 1.
Generative Adversarial Networks Training Process
The key components of all GANs are the generator and discriminator models. These two neural networks contest with each other adversarially during the training process.
The generator takes in random noise as input and transforms it into synthetic outputs, such as images. The goal is to generate these synthetic examples that resemble real samples from a target dataset.
The discriminator model takes in samples from the real dataset, as well as the newly generated synthetic samples from the generator. It attempts to distinguish real samples from fake ones.
The two models are trained simultaneously, with loss functions defined such that the generator is rewarded for fooling the discriminator, and the discriminator is rewarded for properly identifying real vs. fake samples. The overall adversarial framework drives the generated outputs to become more and more realistic.
More specifically, GAN training works by alternating between the following two steps:
- Train the discriminator on batch of real samples and generated samples, updating based on its ability to classify them correctly.
- Generate a batch of new samples with the generator, then train the generator to try to maximize the discriminator's probability of misclassifying these synthetic samples as real.
As training progresses, the competition drives both models to improve - the discriminator gets better at distinguishing real from fake, and the generator gets better at producing fakes that are convincing. The end result is a generator model that can create highly realistic synthetic data.
Different loss functions can be used for each model, such as binary cross-entropy loss or Wasserstein loss. The choice of loss function impacts model stability and convergence.
Why Are They Useful?
GANs have been used in a variety of applications:
- Image Generation: Creating realistic images from scratch.
- Data Augmentation: Increasing the size of data sets by generating new examples.
- Style Transfer: Changing the artistic style of images.
- Super-Resolution: Enhancing the quality of low-res images.
- Text-to-Image Generation: Generating realistic images from textual descriptions.
And many more!
Types of GANs
Since the original GAN paper, many researchers have developed significant improvements to the GAN framework. Some notable GAN variants include:
Conditional GANs
Conditional GANs enable greater control over the generator by providing additional conditional information to both the generator and discriminator. For example, class labels that specify the type of image to generate.
This allows conditional GANs to do things like generate images based on specific text descriptions. The added control means the generator can synthesize a more diverse range of high-quality samples.
CycleGANs
CycleGANs aim to learn mappings between different domains without paired input-output examples. For instance, mapping photos between summer and winter settings. The "cycle" in CycleGAN refers to the circular flow of information.
CycleGANs introduce cycle consistency losses that ensure mappings are invertible between domains. This makes them very useful for tasks like style transfer and unsupervised image translation.
StyleGANs
StyleGANs incorporate ideas from style transfer to give fine-grained control over the generator's outputs. Separate learned layers control high-level attributes of generated images like pose, while other layers control stylistic qualities like color scheme and lighting.
This improves both the quality and diversity of outputs. For example, StyleGANs can smoothly interpolate between variations of faces by modifying the style layers. They are considered state-of-the-art for unconditional GANs focused on image synthesis.
There are many other types like DCGANs, InfoGANs, Wasserstein GANs, and more. Each modify or add constraints to the adversarial framework for improved training stability and better quality on synthesized outputs.
Challenges and Limitations
GANs aren’t perfect. They have their own set of challenges:
- Mode Collapse: Mode collapse occurs when the generator starts to generate a very limited variety of samples, usually focusing on producing just one or a few kinds of data. This means that the generator has found some "trick" to fool the discriminator and starts exploiting it, instead of generating a wide range of realistic samples.
- Training Instability: GANs are notoriously hard to train. The generator and the discriminator are both trying to optimize different loss functions, often leading to oscillations where neither reaches an optimum
- Resource Intensive: Training GANs typically requires a significant amount of computational resources. This includes not just the hardware but also the computational time, which makes it prohibitive for smaller organizations and researchers to work on GANs.
For more on these challenges, here is an insightful paper that covers them in depth.
The Future of GANs
GANs are still a rapidly evolving field. Here are some exciting directions as GAN research continues:
- New architectures and training methods - better techniques for stable training and high-quality generators could unlock new applications. Hybrid models that combine GANs with other methods like autoencoders are also promising.
- High-resolution generation - current GANs still have limits in generating ultra-high-res images, video, and audio. More work is needed to scale up to resolutions useful for production.
- Control and interpretability - giving users more intuitive control over generated content through conditional inputs, style vectors, or editing tools.
- Ethical considerations - carefully managing potential misuse, like for deepfakes, and maintaining transparency will be critical as GANs advance.
GANs have already made a sizable impact in just a few years. As the technology continues rapidly developing, we're likely to see GANs push the frontiers in speech synthesis, video game graphics, simulations, medical imaging analysis, and many other domains.
References
- https://dl.acm.org/doi/pdf/10.1145/3422622
- https://www.sciencedirect.com/science/article/pii/S2667096820300045
- https://ieeexplore.ieee.org/stamp/stamp.jsp?arnumber=8039016
- https://proceedings.neurips.cc/paper/2018/hash/d645920e395fedad7bbbed0eca3fe2e0-Abstract.html
- https://proceedings.neurips.cc/paper/2021/hash/076ccd93ad68be51f23707988e934906-Abstract.html